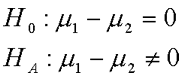 |
|
|
|
|
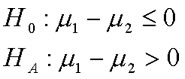
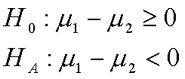
Study Design
The t-test for independent means requires that there is no overlap between the two groups in the research design. This is what we mean by "independent means". In this design, we collect data from two separate samples. We only use the t-test for independent means when we are studying two groups; a different statistic is used when there are more than two groups. In this test, we compare the observed difference between the two sample means (M1 - M2) to the expectation that there is no difference in the population (m1 - m2 = 0).
Available Information
The t-test for independent means compares the difference between two independent sample means to an expectation about the difference in the population. For this test, we do not need to know the population parameters. As long as the null hypothesis reflects no difference in the population, then the value of m1 - m2 needed for our statistical hypothesis is known (0). In t-tests, we estimate the population variances/standard deviations from sample data (S).
Test Assumptions
All parametric statistics have a set of assumptions that must be met in order to properly use the statistics to test hypotheses. The assumptions of the t-test for independent means are listed below.
|
|
Random sampling from a defined population |
|
|
Interval or ratio scale of measurement |
|
|
Scores in the populations are normally distributed |
|
|
The population variances are equal |
When reading the psychological literature, we can find many studies in which many of these assumptions are violated. Random sampling is required for all statistical inference because it is based on probability. Random samples are difficult to find, however, and psychologists and researchers in other fields will use inferential statistics on nonrandom samples and discuss the sampling limitations in the article. We learned in our scale of measurement tutorial that psychologists will apply parametric statistics like the t-test for independent means on approximately interval scales even though the tests require interval or ratio data. This is an accepted practice in psychology and one that we use when we analyze our class data. Finally, the assumption that the difference scores are normally distributed in the population is considered "robust". This means that the the statistic has been shown to yield useful results even when the assumption is violated. The central limit theorem tells us that even if the population distribution is unknown, we know that the sampling distribution of the mean will be approximately normally distributed if the sample size is large. This also applies to the means of difference scores and helps to contribute to the t-test being robust for violations of normal distribution. The t-test for independent means is not robust for violations of the assumption of equal variance. The shape of the sampling distribution of the mean is a function of the variance/standard deviation in the population and the size of the sample drawn from the population. If the populations have different variances, then we do not know what the shape of the sampling distribution of the difference should be. This is a serious problem for our statistic. Computer programs offer a solution by testing whether the variances are equal and providing a mathematical correction when they are not. If we are conducting a one-tailed test, the data are highly skewed, and the variances are unequal, we should consider a different test.
| Click here to review the one-sample Z-test: | |
| Click here to review the one-sample t-test: | |
| Click here to review the t-test for dependent means: | |
| Click here to return to the main page: |